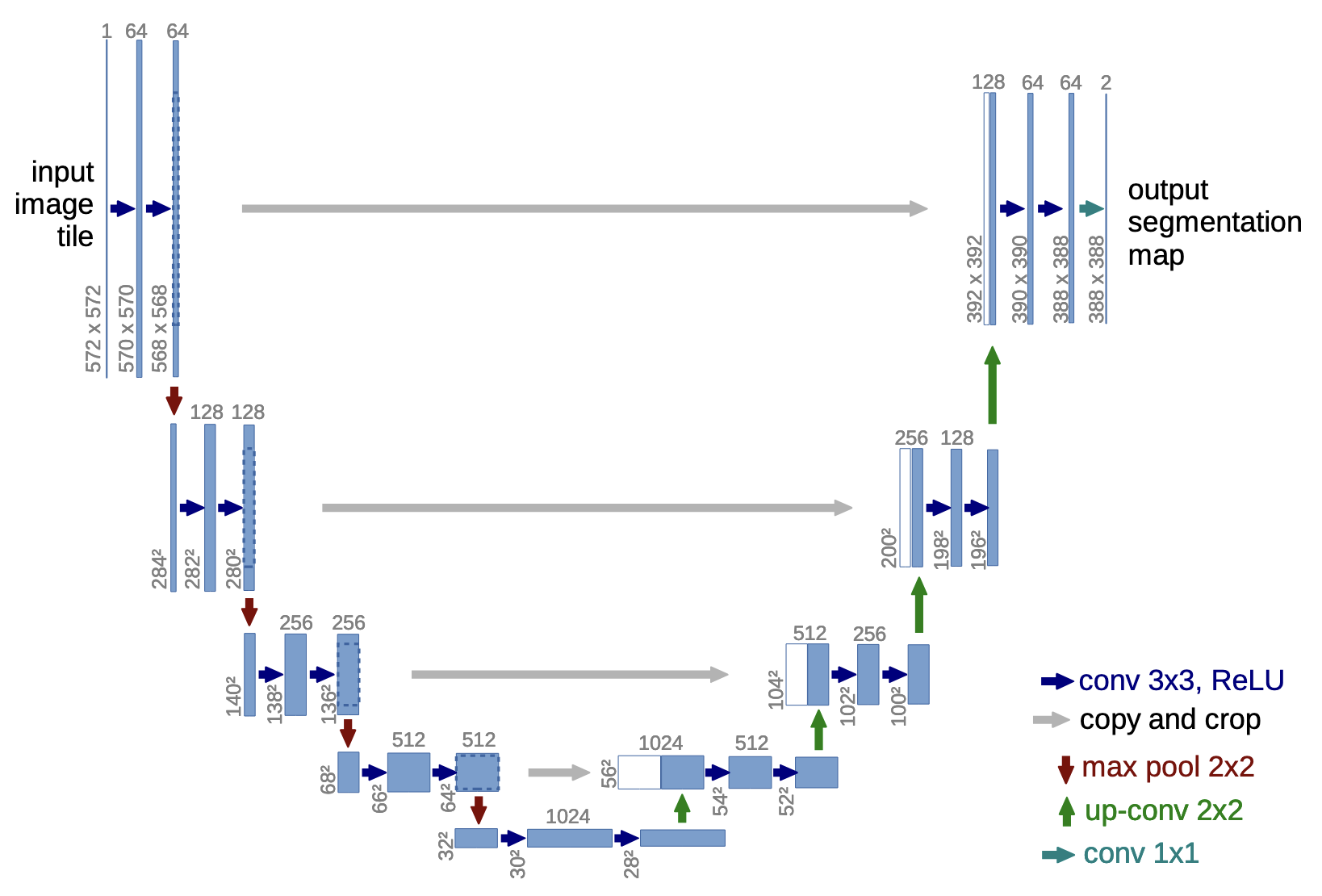
U-Nets are a special type of neural network developed for (Semantic) Image Segmentation. The network is based on a convolutional neural network.
The network consists of:
- An encoder part: Left side
This path consists of successive convolutions and pooling layers.
Purpose: Capture contextual information (meaning behind pixels) from the image by reducing its spatial dimensions. - Bottleneck: The deepest layer at the bottom. The image has been downsampled to its fullest extent and its contextual features are fully encoded. We expect high level information to be encoded here.
- Decoder: Right side of the network
This path uses upsampling layers to reconstruct an image (usually a segmentation mask) to the original size of the input image. - Skip connections: A skip connection, bridging a path between the encoder and decoder part of the network. It allows the decoder to rely not only on compressed features, but also on the more raw data.
*Feeds the output of one layer as the input to a further layer.
Input: Images. Each pixel is classified.
Output: Segmentation mask.
Details: Encoder
Each block is composed of:
- First Convolutional Layer
- Second Convolutional Layer
- Maxpooling Layer
The amount of these blocks is a hyperparameter.
class DoubleConv(nn.Module):
def __init__(self, in_channels, out_channels):
super().__init__()
self.conv_op = nn.Sequential(
nn.Conv2d(in_channels, out_channels, kernel_size=3, padding=1),
nn.BatchNorm2d(out_channels),
nn.ReLU(inplace=True),
nn.Conv2d(out_channels, out_channels, kernel_size=3, padding=1),
nn.BatchNorm2d(out_channels),
nn.ReLU(inplace=True)
)
def forward(self, x):
return self.conv_op(x)
class DownSample(nn.Module):
def __init__(self, in_channels, out_channels):
super().__init__()
self.conv = DoubleConv(in_channels, out_channels)
self.pool = nn.MaxPool2d(kernel_size=2, stride=2)
def forward(self, x):
down = self.conv(x)
p = self.pool(down)
return down, p
What is a channel here?
See convolutional neural network
For an RGB image: 3 input Channels (red + green + blue)
A convolutional layer is composed of filters. Each filter is applied on the entire input. While encoding, we decrease the "image size", while increasing the amount of channels. Each channel encodes a certain detail, an information that helps us reconstruct the mask. These details go from low level to very high level/abstract.
Example: Lines detected -> Shapes detected -> tree detected -> acorn detected
Details: Decoder
class UpSample(nn.Module):
def __init__(self, in_channels, out_channels):
super().__init__()
self.up = nn.ConvTranspose2d(in_channels, in_channels//2, kernel_size=2, stride=2)
self.conv = DoubleConv(in_channels, out_channels)
def forward(self, x1, x2):
x1 = self.up(x1)
x = torch.cat([x1, x2], 1)
return self.conv(x)
Details: skip connections
Full implementation
class UNet(nn.Module):
def __init__(self, in_channels, num_classes):
super().__init__()
self.down_convolution_1 = DownSample(in_channels, 64)
self.down_convolution_2 = DownSample(64, 128)
self.down_convolution_3 = DownSample(128, 256)
self.down_convolution_4 = DownSample(256, 512)
self.bottle_neck = DoubleConv(512, 1024)
self.up_convolution_1 = UpSample(1024, 512)
self.up_convolution_2 = UpSample(512, 256)
self.up_convolution_3 = UpSample(256, 128)
self.up_convolution_4 = UpSample(128, 64)
self.out = nn.Conv2d(in_channels=64, out_channels=num_classes, kernel_size=1)
def forward(self, x):
down_1, p1 = self.down_convolution_1(x)
down_2, p2 = self.down_convolution_2(p1)
down_3, p3 = self.down_convolution_3(p2)
down_4, p4 = self.down_convolution_4(p3)
b = self.bottle_neck(p4)
up_1 = self.up_convolution_1(b, down_4)
up_2 = self.up_convolution_2(up_1, down_3)
up_3 = self.up_convolution_3(up_2, down_2)
up_4 = self.up_convolution_4(up_3, down_1)
out = self.out(up_4)
out = torch.sigmoid(out)
return out
{python}out = torch.sigmoid(out)line, which is used on binary problems. Use something else if it is not a binary problem.model = UNet(in_channels = 3, num_classes = 1)
# example input
input = np.random.randint(size=(256, 256))
input = input[None, None, :, :] # batch_size, input_channels, x_dim, y_dim
input = torch.tensor(input, dtype=torch.float32)
output = model(input)
Loss functions for U-net
See Loss functions