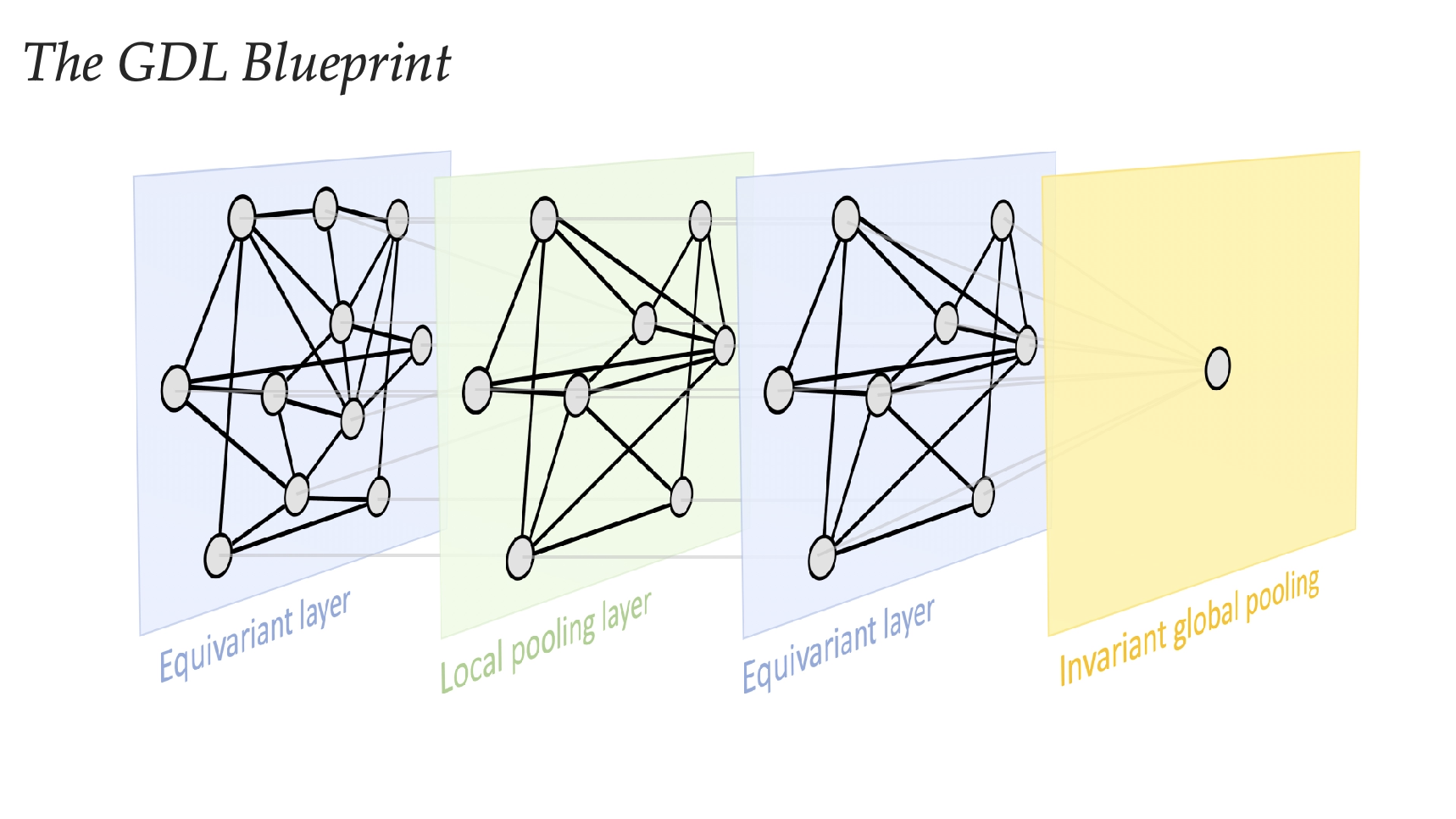
Part of How to think about model architecture
The idea of scale separation, in a ml context, is to recognise and exploit, that different aspects/patterns in data appear on different scales.
Example:
CNN for image classification
- The early layers focus on low level details. small scale features
- The middle layers combine the low level features to form more complex patterns
- The later layers combine the middle layer features into high level semantic expressions. The scale is big, because the neurons of the later layers have a large receptive field.
Graph Neural Networks
- The early layers focus on nodes immediate surroundings (or just the node itself)
- Middle Layers focus on more surroundings
- Later layers focus on even more surroundings
Notice how exactly like CNNs, the receptive field expands the more
{python}GCNConv layers we have. These Layers, even if they work differently share a similar name because the abstract, scale separation is present in both.Consequences for How to think about model architecture
Note that the choice of the layers and whether they are equivariant or not is not part of the scale separation theory.
One consequence of scale separation is to design "blocks" that analyse data at a specific scale. These blocks always end with a pooling layer, that increases the receptive field (because there should be less higher level features than lower level).