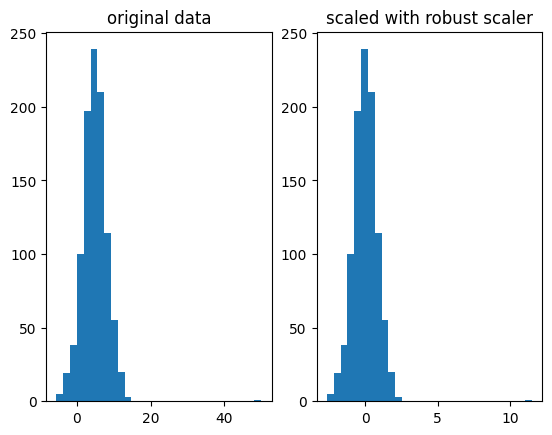
robust scaling distorts the distribution
Z-scores are a common normalization method applied to data that has outliers. It does not require the data to be normally distributed.
Math
{python}normalized_data = (data - median) / IQR
with $$IQR = 75_{th\ percentile} - 25_{th\ percentile}$$
This should be very robust to outliers, however it doesn't create nice normalized standard deviations or guarantee a certain value range.
Implementation
In practice people use the RobustScaler from scikit-learn to normalize their features.
from sklearn.preprocessing import RobustScaler
scaler = RobustScaler()
X_train_scaled = scaler.fit_transform(X_train)
# To avoid bleeding from test set: Use scaler's μ and σ from training
X_non_train_scaled = scaler.transform(X_non_train)
What if we do not want to shift the distribution?
This could be if we have sparse data for example
Simply tell it not to center the data. I would recommend also shifting the IQR to avoid it being zero (75th quantile) if the data is very sparse.
scaler = RobustScaler(with_centering=False, quantile_range=(10, 90))
Example:
notice the outlier at 50, the scaling still works. For a singular outlier, standard scaler, z-score normalizationwould've also worked, but you get the idea.