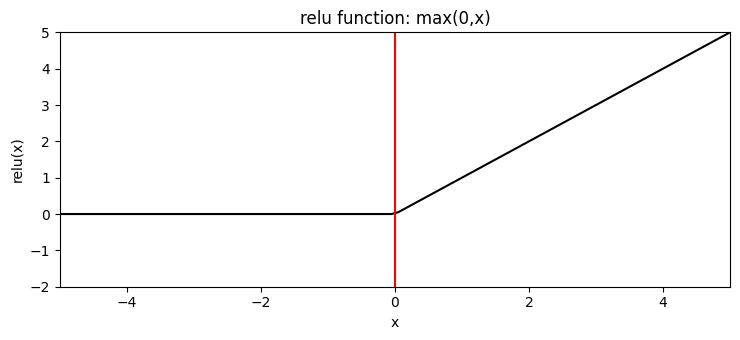
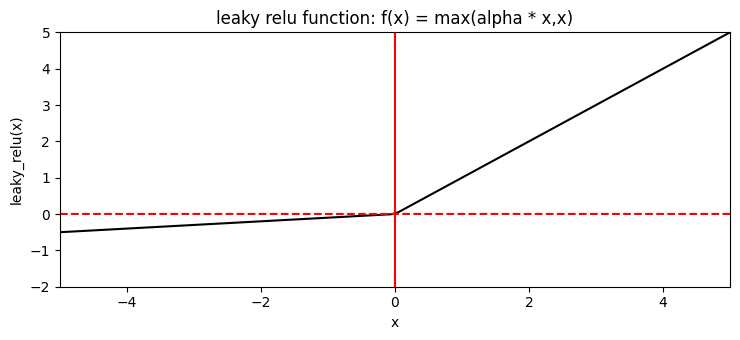
Most used activation function. Sometimes people use "leaky RELU" to avoid dead neurons.
It looks like this activation function cannot be derived. We fix this by simply setting the derivation to 0 or 1 at x=0.
{python} torch.nn.ReLU()
Torch allows us to set an in-place parameter. If set to true, it doesn't create a copy of the input, it saves memory and helps with computations, however if the layer is needed later (skip connections or other) that is obviously an issue.
Advantages
- So cheap to compute
Neural networks that use this activation function after each/most layers are called Relu Neural Network
Leaky ReLU
Trivia
In one course a model using the ReLU activation function with linear layers was called a "relu neural network". I wouldn't use this term outside of this one course though, I don't think its an established term.