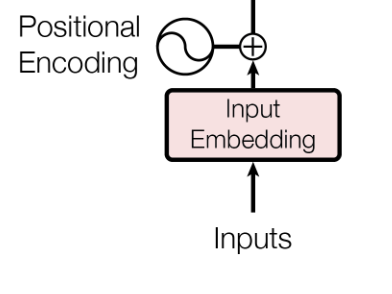
Transformers process data simultaneously. All at the same time. This makes them very efficient, however the information about the position is lost. Positional encoding aims to combine the data and its position, and feed that to the transformer.
Definition
The positional encoding is not just a number that tells you which value is first. It literally gets added to the input, allowing the model to learn much more complex encodings than just this token comes first or second.
Don't question it too much, it just works. Maybe ask a professor about it one day.
class PositionalEncoding(nn.Module):
def __init__(self, d_model, max_seq_length):
super(PositionalEncoding, self).__init__()
positional_encodings = torch.zeros(max_seq_length, d_model)
# array with values from 0 to max_seq_length - 1
position = torch.arange(0, max_seq_length, dtype=torch.float).unsqueeze(1)
div_term = torch.exp(torch.arange(0, d_model, 2).float() * -(math.log(10000.0) / d_model))
positional_encodings[:, 0::2] = torch.sin(position * div_term)
positional_encodings[:, 1::2] = torch.cos(position * div_term)
# We are saving the positional encodings for if the model is moved to a different device. It registers the tensor as a non-trainable buffer within the module.
self.register_buffer('positional_encodings', positional_encodings.unsqueeze(0))
def forward(self, x):
return x + self.positional_encodings[:, :x.size(1)]
Notice that we are creating an entire model. This can then be used as a layer in other models. It would've totally been acceptable to just do it as a function, but this is prettier and the people who came up with the idea to use it for transformers are very used to writing models so they did that.
{python} def __init__(self, d_model, max_seq_length):
d_model is the dimension of the model. It is the size of an input token. This depends on the embedding layer.
max_seq_length is the maximum length of the input sequence. The amount of tokens.
{python} positional_encodings = torch.zeros(max_seq_length, d_model)
This tensor will hold the positional encodings. Its shape allows a 1 at a different place for each input token.
About the shape: max_seq_length is clear, we need one position for each input. There can be up to max_seq_length inputs.
The sinus stuff seems to be some math trick, I will look at it on a later date.