Piecewise affine functions
Affine function:
Piecewise Affine function:
Why Relu layers create piecewise affine function
Linear layers:
Relu Layers:
Therefore a ReLU neural network is simply an affine function with a high number of "pieces".
Why Piece-wise affine functions are always overconfident if far away from the data.
If you move far away into one direction, at some point you will stay in a linear space until infinity (following that direction). Therefore at some point you will approach either 0 or 100% class probability, therefore 100% confidence in your prediction.
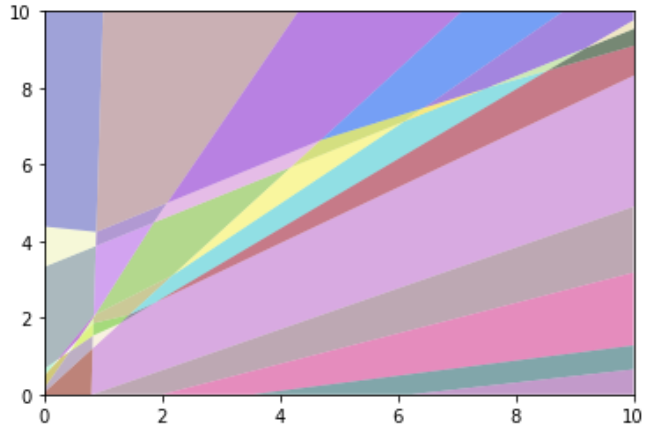
The coloured areas are the affine parts. Ignore the white dotted lines.
Why this cannot be fixed with temperature scaling.
Temperature scaling is a post processing technique to make neural networks calibrated. It divides the the logits vector (neural network output) by a learnt scalar parameter. Since our theory is valid for any
Why this cannot be fixed with Softmax:
This does not change the relative magnitude of the logits. So if the original distribution is heavily skewed, then the softmax distribution will be as well.
How to fix it?
One idea are Bayesian Neural Networks networks. But basically the problem is unsolved.