K-Fold cross validation increases the certainty and trust in the models accuracy score.
When to use
- When you have limited amount of data
- When you have doubts about the models accuracy score
How it works
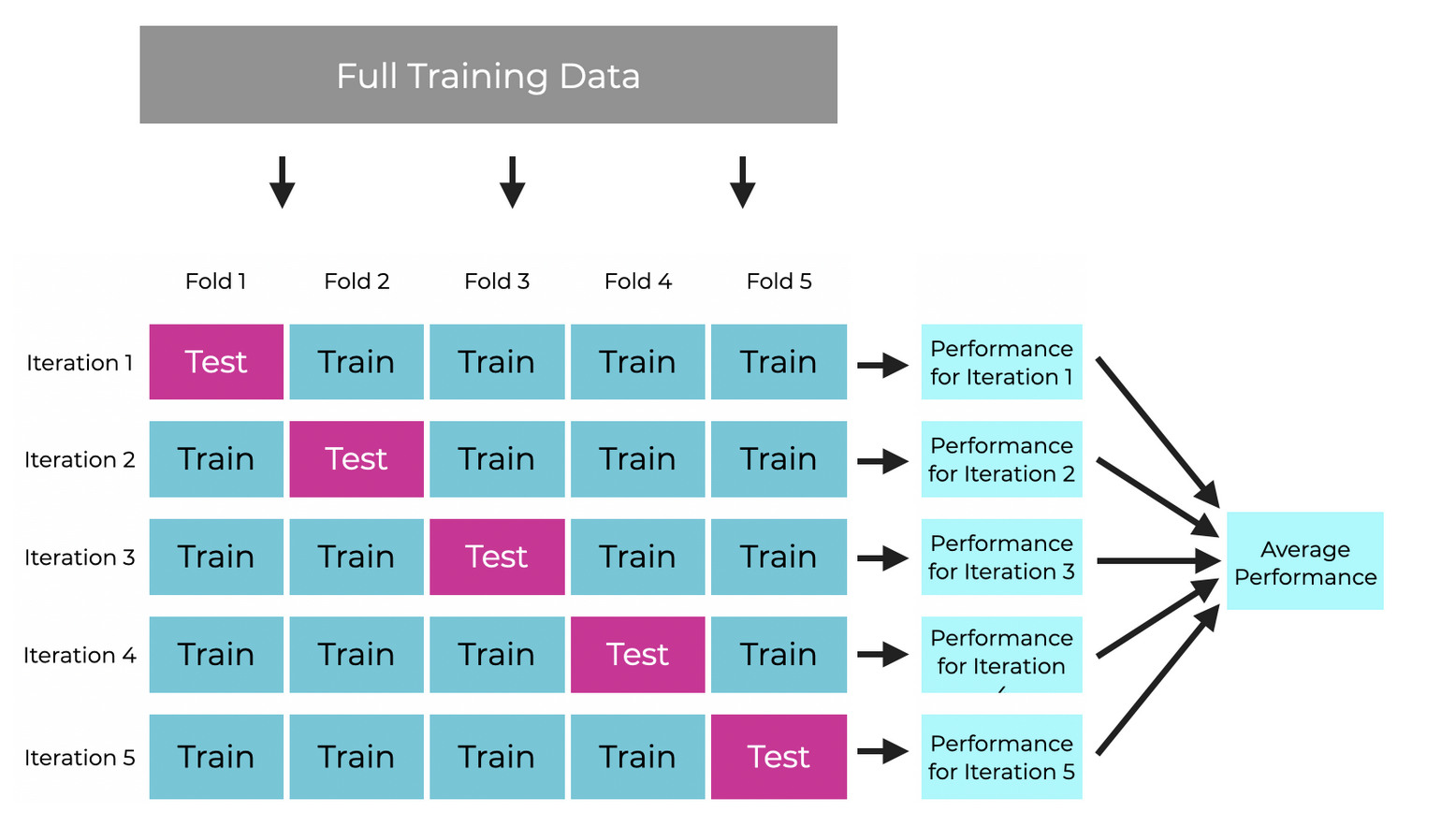
How to choose K:
Just make sure that the test dataset is still large enough. Don't overthink it.
Example: 100 datapoints, test dataset is about 20% => k = 5 would be appropriate.
Implementation
Let's say the data is in arrays or a dataframe:
from sklearn.model_selection import cross_val_score, RepeatedKFold
from sklearn.linear_model import LogisticRegression
X, y = get_dataset(...)
estimator = LogisticRegression()
rkf = RepeatedKFold(n_splits=5, n_repeats=10)
scores = cross_val_score(estimator, X, y, cv=rkf, n_jobs=-1)
print("Average Score:", scores.mean())
print("Standard Deviation:", scores.std())
cross_val_score
Input:
- estimator: the model type that will be trained and evaluated
- X, y: The full dataset
- cv=rkf: The cross validation strategy used. In this case this means that we split into 5 folds, and repeat the process 10 times. The splits are random each time. Therefore we train and evaluate 50 times in total.
Output: The accuracy scores from each individual trained model.
Wait this is way too high level, doesn't work for my use-case:
I agree, that's not coding anymore, its way too simple. You can simply write your own loop(s):
indices = np.array(range(len(X)))
np.random.shuffle(indices)
k = 5 # amt of folds
fold_size = len(patients) // 5
fold_accuracy_scores = []
repeats = 10
for repeat in range(repeats):
print(f"Repeat {repeat + 1}/{repeats}")
for fold in range(k):
start = fold * fold_size
end = start + fold_size if fold != k - 1 else len(X)
test_indices = indices[start:end]
train_indices = np.concatenate([indices[:start], indices[end:]])
train_patients = patients[train_indices]
test_patients = patients[test_indices]
X_train, y_train = get_dataset(train_patients)
X_test, y_test = get_dataset(test_patients)
fold_accuracy_scores.append(train_log_regression(X_train, y_train, X_test, y_test))
avg_accuracy = np.mean(fold_accuracy_scores)
std_accuracy = np.std(fold_accuracy_scores)
print("\nAverage accuracy:", avg_accuracy)
print("Standard Deviation:", std_accuracy)
Consequences for the final model
K-fold cross validation is a tool to get an accuracy score during development.
The architecture, hyperparameters etc... found via investigating and improving that accuracy score, are then used in a final training using the entire dataset, without test data.
After deployment the accuracy in practice should be monitored. If it deviates too much from the score found via cross validation it should be investigated.