Designing models is mostly a trial and error process. However, there are ways of thinking that help. Furthermore you can often guarantee that certain things will not work.
An example is: Interpolation. Very basic concept, but crucial for machine learning. Geometric deep learning for example, very simplified, asks, which methods/layers will make interpolation easier.
Geometric deep learning
Following the principles below is a good idea, but a certain amount of robustness for it to work on real life data will require bending those rules in architecture a little.
Apply the Erlangen Programme mindset to the domain of deep learning
https://arxiv.org/pdf/2104.13478
https://www.youtube.com/watch?v=PtA0lg_e5nA&list=PLn2-dEmQeTfQ8YVuHBOvAhUlnIPYxkeu3
Base theory
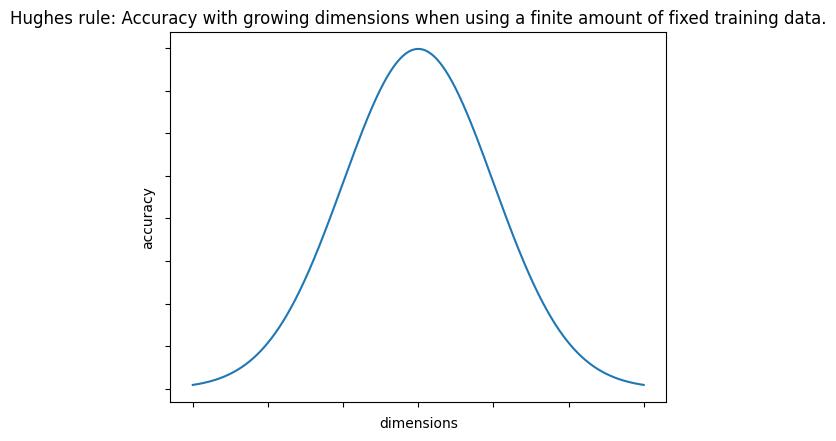
The goal is to somehow get around the curse of dimensionality:
As the number of features/dimensions grows, the amount of data we need to generalize accurately grows exponentially.
Hughes/Peaking phenomenon:
With a fixed number of training samples, the average (expected) predictive power of a classifier or regressor first increases as the numbers of dimensions or features is used is increased but beyond a certain dimensionality, the accuracy starts deteriorating.
We do this by exploiting invariances. things where the "dimension" doesn't matter.
Example: Convolutional Layers. These layers doe not care about the location of the "object" that we try to detect -> translation invariance.
Here is an overview of the different invariances achieved by basic model layers.
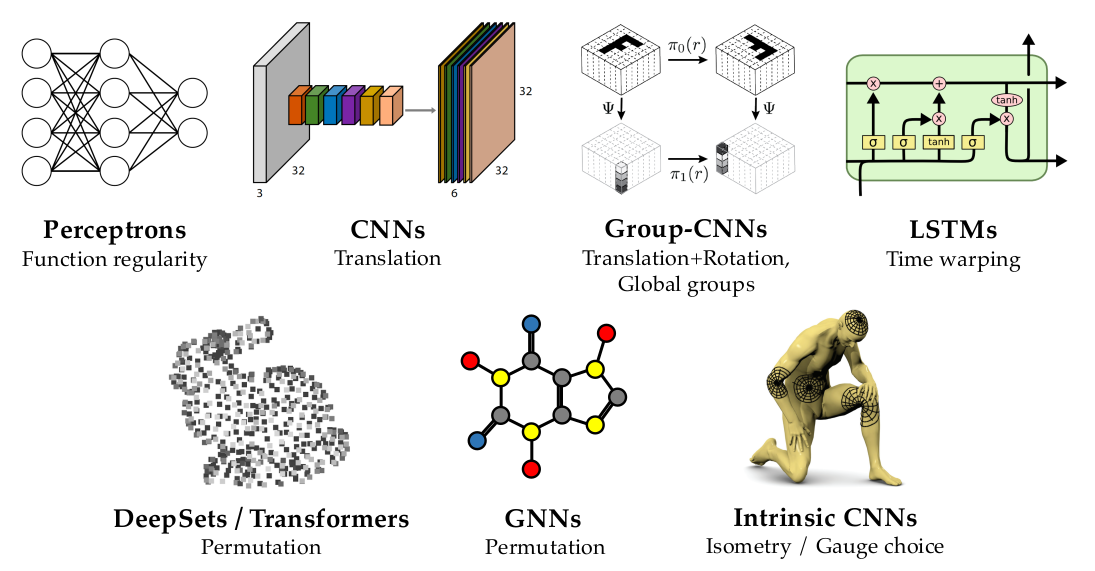
Invariances from the label:

Invariant to the rotation.
Equivariance
A mathematical property, where a transformation to the input leads to a predictable transformation of the output of a function.
Equivariant Networks: Networks designed to respect and leverage the property of equivariance in their architecture.
Examples:
- CNNs are translation invariant
- Group Equivariant Convolutional Networks are invariant in:
- Rotations
- Translations
- Reflections
- Equivariant Graph Neural Networks: operate on nodes, and are therefore equivariant to permutations in the nodes (the order of the nodes does not change the output in an unpredictable way)
Learning under Invariance
| Effect of Invariance | Impact on Training |
|---|---|
| Reduces hypothesis space | Makes training more efficient, needs fewer samples |
| Improves generalization | Helps recognize patterns even in unseen transformations |
| Changes optimization | Shared parameters speed up learning and improve gradient flow |
| Reduces computational cost | Needs fewer parameters to learn the same function |
Scale separation
Part of How to think about model architecture
The idea of scale separation, in a ml context, is to recognise and exploit, that different aspects/patterns in data appear on different scales.
Example:
CNN for image classification
- The early layers focus on low level details. small scale features
- The middle layers combine the low level features to form more complex patterns
- The later layers combine the middle layer features into high level semantic expressions. The scale is big, because the neurons of the later layers have a large receptive field.
Graph Neural Networks
- The early layers focus on nodes immediate surroundings (or just the node itself)
- Middle Layers focus on more surroundings
- Later layers focus on even more surroundings
{python}GCNConv layers we have. These Layers, even if they work differently share a similar name because the abstract, scale separation is present in both.Consequences for How to think about model architecture
One consequence of scale separation is to design "blocks" that analyse data at a specific scale. These blocks always end with a pooling layer, that increases the receptive field (because there should be less higher level features than lower level).


Symmetry for Sets
Sets are a very simple version of graphs. We want the output of the model to be equivariant to how the set is stacked.
Example:
We have 5 objects:
0, 20, 50, 98, 17
These are then moved into a tensor and given to the input layer of our model. This set does not have an inherent order, the input tensor however does due to the way data is saved in tensors.
This order is nonsensical, meaning it appears randomly without adding any information to the original (unordered) set whatsoever. Therefore, our model should be equivariant to any permutations of the input tensor.
f being our model, y our prediction.
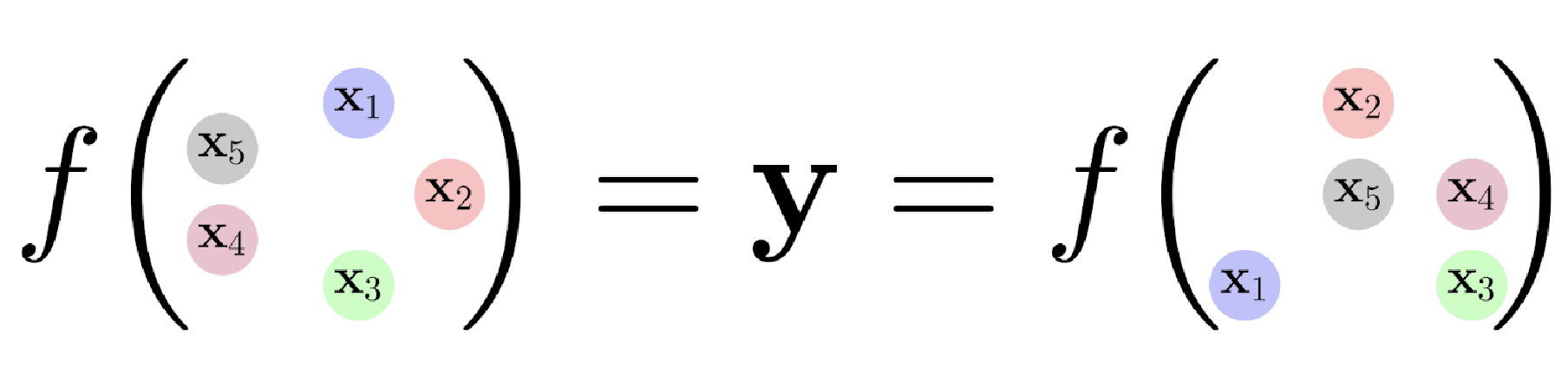
COMPLETE ONCE DEEPSETS HAVE BEEN UNDERSTOOD
Symmetry of graph predictions
Let's assume a simple form of graph prediction, where we are trying to classify each node.
Symmetry of graph predictions means, that the model predicts one prediction per node. The mapping: Input Node -> Class needs to be equivariant, meaning if node 42 is mapped to class X, and then the input graph is permuted, that node 42 is moved a few places down in the input tensor, it still gets mapped to 42, since the Graph is still exactly the same. It just got permuted which is simply an (at least we want it to be) inconsequential action on graphs.
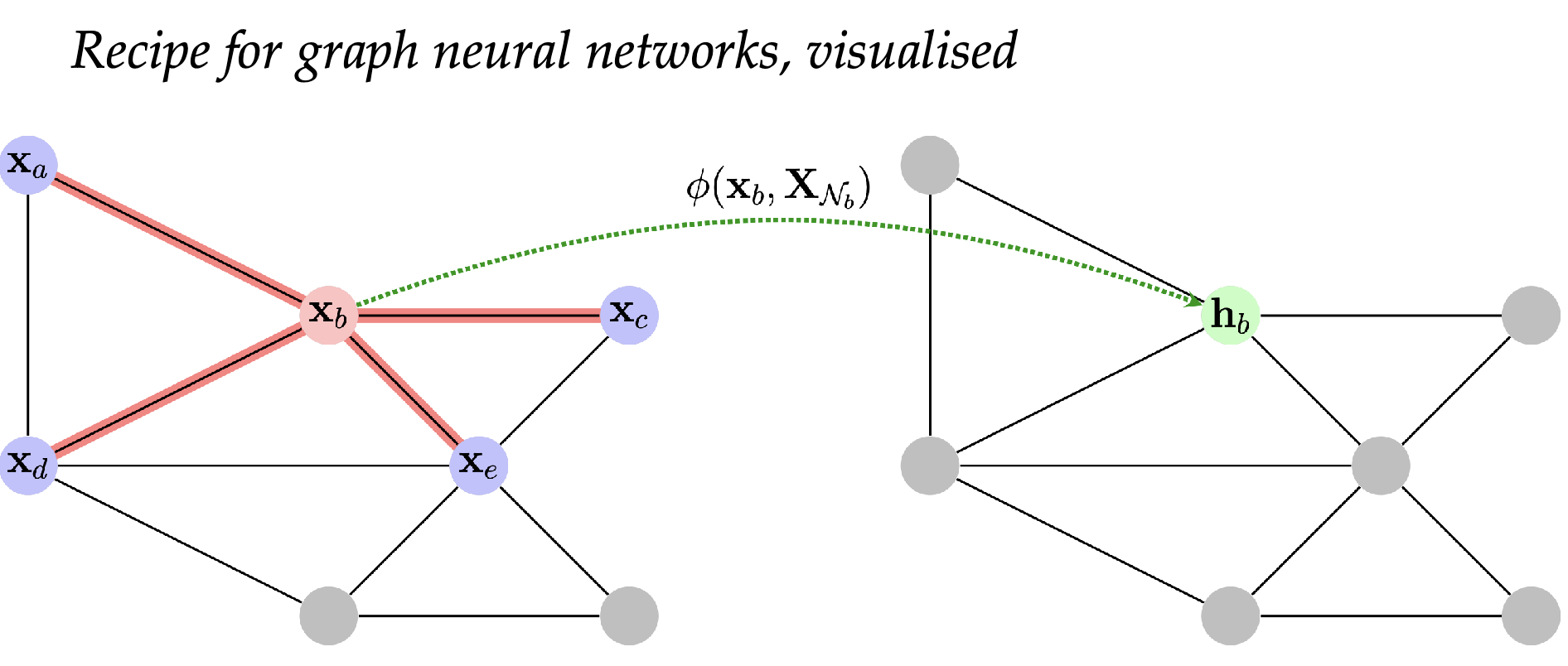
Phi operation being done on each node and producing one prediction h for each node.
more predictions on graphs
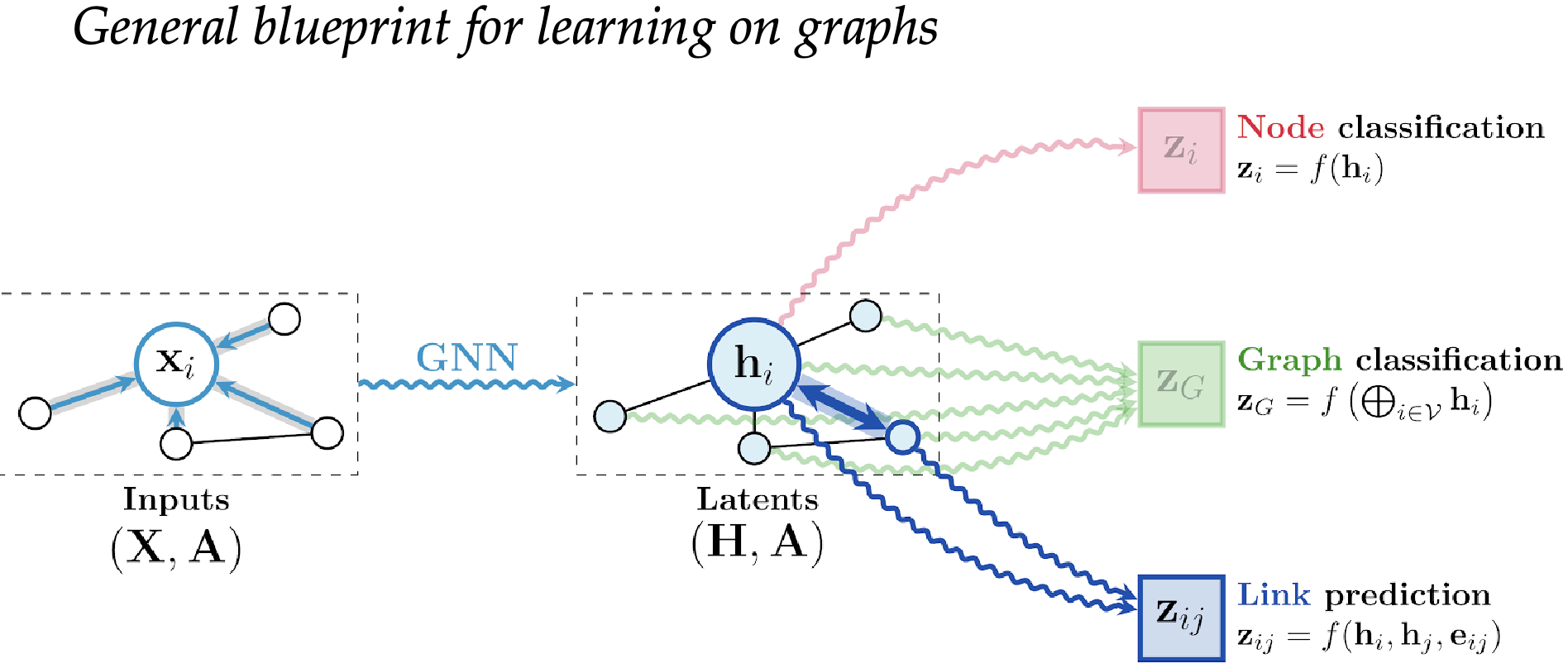
Divers
Physics informed neural networks
Dietmar shared this link: https://en.wikipedia.org/wiki/Physics-informed_neural_networks
Those are networks that aim to incorporate physical laws into their loss/training. While theoretically possible, to also include it into their architecture, it seems hard and I haven't found an example that actually did it.
The base idea is the same though, include what you already know into the models architecture, I don't think this is easily applicable for general problems.