Models can usually not deal with NaN values, they need something.
Types of missing values
the type of missing values influences how we will replace or fill in the values.
| Type of missing data | missing values depend on the missing values themselves? | missing values depend on the observed values |
|---|---|---|
| MCAR | No | No |
| MAR | No | Yes |
| MNAR | Yes | Yes |
Types of replacements:
Deletion
Don't do it
Imputation:
Replace the missing values with estimates.
Mean/Median/Mode imputation
Title speaks for itself. Careful this might introduce a bias if the missing data is not randomly distributed.
df.loc[:,['age']] = df['age'].fillna(df['age'].median())
K-Nearest Neighbors (KNN Imputation)
This method finds the closest data points (neighbors) based on available features and uses their values to estimate the missing value. KNN is useful when you have a lot of data and the missing values are scattered.
Model-based Imputation
Have a model predict the missing data.
Implementation
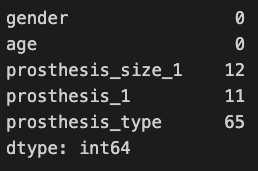
look at the missing data:
{python}print(df.isna().sum())