You have a model and a validation dataloader. Please implement f1 score calculation on the validation dataset. Assume that the problem is binary.
?
binary problems
from sklearn.metrics import f1_score
import torch
y_gt = []
y_bin_pred = []
model.eval()
with torch.no_grad():
for X, y in val_dataloader:
pred = model(X)
prob = torch.sigmoid(pred)
# maybe this require .flatten() and .cpu()
y_bin_pred.append(prob > 0.5)
y_gt.append(y)
f1 = f1_score(y_bin_pred, y_gt)
print(f"F1 Score: {f1:.2f}")
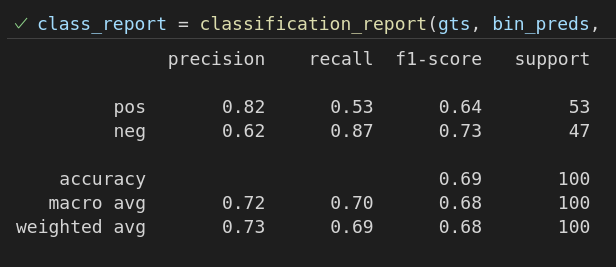
You have a binary classification problem. You have an array with the predictions probabilities for the positive class from the model, and one array with the label (1 for pos, 0 for neg). Please create a classification report for that model.
?
Implementation
from sklearn.metrics import classification_report
y_bin_preds = np.array(y_pred) > 0.5
print("Confusion Matrix:\n", classification_report(y_test, y_bin_preds, target_names=["pos", "neg"])) # target names: 0, 1, 2, ..., str labels in that order