loss_fn = torch.nn.CrossEntropyLoss()
Like most loss functions, the cross-entropy-loss takes the output of the model (predicted probability) and the ground truth (actual probability) and calculates the distance between the two in a fancy way which has some nice properties.
Potential issues
Imbalanced classes
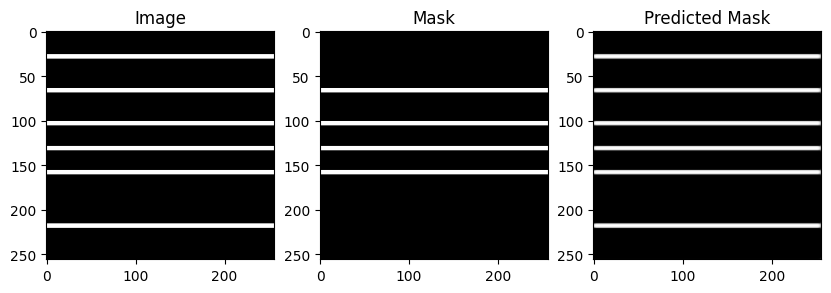
The model achieves ~90% accuracy and stops learning. It is meant to ignore the white stripes at the bottom and top.
Cross entropy loss treats every class the same. So if you have heavily imbalanced classes (like trying to segment very small tumors), then there is a high chance, that the model will just start predicting the dominant class everywhere. It will be mostly correct, yet completely useless.
Solution: The minority classes need to be weighed higher, missing the tumor needs to be heavily punished. The simples way (during coding) would be to use a different loss function.
No task specific logic, context
probably applies to most loss functions
CrossEntropyLoss ignores logical issues like pixels that need to connect not connecting, can create noisy segmentations, etc...
It can be an option to combine this loss and another loss to remedy some of its issues combined soft dice and cross entropy loss.