Why do we want normalized and centered data?
I could go into math here, but I will not. I believe that most tools and computations on data could be adapted to work on uncentered, non-normalised data. However most tools, computations by default assume the data to be normalised and won't work as well if the data is not normalised or centered. They may become unstable or require bias terms.
Normalised data does have a lower condition number, because a NN aren't able to look at multidimensional data that is not on the same scale without having a bias for the larger dimension.
If interpretability is super important, then you could decide not to, or only center/normalise at the very end.
Furthermore the centering and normalisation are not complex or non-invertable functions. We can and should apply them to any sort of data that is fed into a NN that is not categorical (one-hot encode is better here).
What to do for which type of data
Non-numerical data
You do not normalize or center, you simply one-hot encode.
Numerical data
Normally distributed data
This is the data we most commonly deal with when handling probabilities.
One method that can deal with moderate outliers is z-score:
Z-scores are a common normalization method applied to data that is normally distributed.
Math
{python}normalized_data = (data - mean) / std
mean and std are robust against moderate outliers.
Implementation
def z_score_normalize(data: np.ndarray):
mean = data.mean()
std = data.std()
normalized_data = (data - mean) / std
return normalized_data
{python}StandardScalerfrom scikit-learn to normalize their features. Under the hood this calculates a z-score.from sklearn.preprocessing import StandardScaler
scaler = StandardScaler()
X_train_scaled = scaler.fit_transform(X_train)
# To avoid bleeding from test set: Use scaler's μ and σ from training
X_non_train_scaled = scaler.transform(X_non_train)
Example
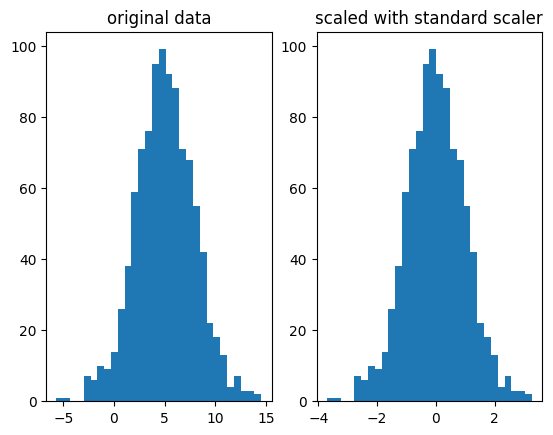
Same distribution and shape, but centered around 0 and with a std deviation of 1.
When not to use
- The distribution is not Gaussian
- There are strong outliers present. (deal with them and then apply it).
An alternative, that can deal better outliers and non gaussian data: robust scaler, normalization
Data with outliers
Z-scores are a common normalization method applied to data that has outliers. It does not require the data to be normally distributed.
Math
{python}normalized_data = (data - median) / IQR
with
This should be very robust to outliers, however it doesn't create nice normalized standard deviations or guarantee a certain value range.
Implementation
from sklearn.preprocessing import RobustScaler
scaler = RobustScaler()
X_train_scaled = scaler.fit_transform(X_train)
# To avoid bleeding from test set: Use scaler's μ and σ from training
X_non_train_scaled = scaler.transform(X_non_train)
What if we do not want to shift the distribution?
This could be if we have sparse data for example
Simply tell it not to center the data. I would recommend also shifting the IQR to avoid it being zero (75th quantile) if the data is very sparse.
scaler = RobustScaler(with_centering=False, quantile_range=(10, 90))
Example:
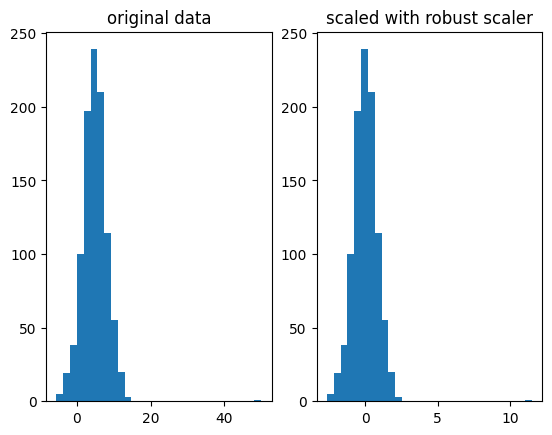
Sparse data
If your data contains mostly zeroes, then you would want to keep it this way, for simpler computation.
Therefore this requires scaling without shifting. One of the simplest methods, would be to divide by the maximum absolute value. Note however that this is not very robust to outliers.
To be more robust to outliers, you can use the Robust scaler, telling it not to center the data.
Edge Cases
Sometimes, the absolute values are important, or certain values are important (like 0s). Any scaling or normalization methods that distort the distribution like the standardscaler or robust scaler cannot be applied. In my example my feature was an array, that gave me the absolute distance from the aortic valve. The position of the aortic valve (the 0) was very important for my model, and applying either the standard scaler, z-score normalization or robust scaler, normalization, made the models performance noticeably worse.
I don't have enough knowledge about Positional Encoding yet, take this part with a grain of salt. Often times, more complex solutions, like Positional Encoding or Embeddings are required to properly give the model the information it needs.
However, if you don't have time to do so, a quick hack would be to simply divide by the maximum value of a feature. Note that this value should be a global maximum to not loose information like the total length.