Any numerical method that uses random sampling with replacement, meaning choosing the best value.
apparently you have to sample from a distribution.
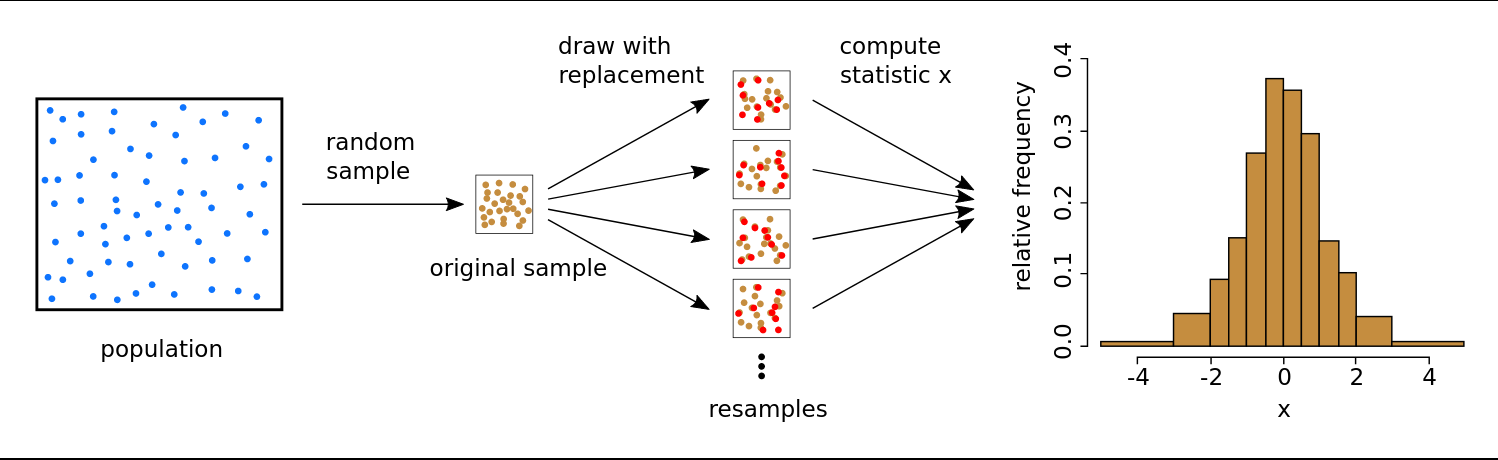
With replacement meaning:
An observation can be observed more than once.
Example: Our original dataframe has N rows. each of our samples will have N rows as well.
this is to have the same dataset size, to have exactly the conditions, just with different data, sometimes this can matter. Same number of calculations, same everything basically.
The rows will differ from the original rows. Row 5 (from the original dataset) might be there 3 times. Row 1 (from the original dataset) might not be there. This is something we want.
pytorch implementation
sample = df.sample(replace=True)