Activation functions introduce non-linearity to a NN. If you have a NN without activation functions, the resulting function is a linear one. If the problem requires a nonlinear function, the NN will never be able to solve it.
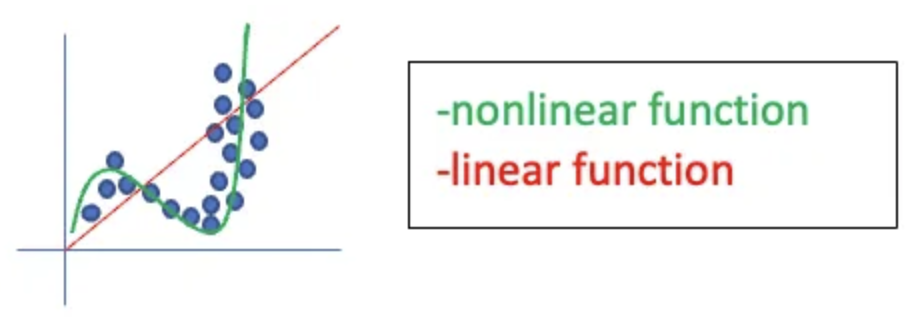
Furthermore, there is little point to do multiple linear layers (of same size) one after the other, because any function could also be represented with a single layer.
There are many different types of activation functions, I will mention most of them here, but only go into details for the ones, that are actually used.
- Sigmoid function: Not used.
Simply better in any way to the sigmoid function.
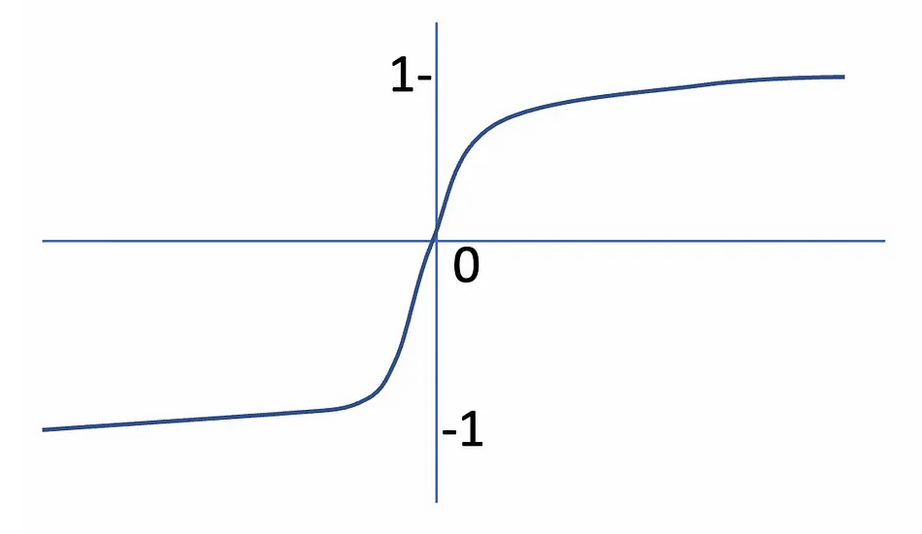
Advantages:
- Outputs a value between -1 and 1
- Zero centered which is great for parameter optimization in the following layers
- output close/likely to be normalized
Data Normalization + Centering
{python} torch.nn.Tanh()
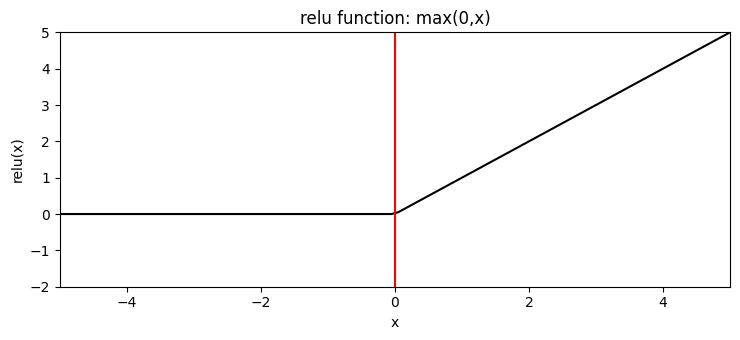
Most used activation function. Sometimes people use "leaky RELU" to avoid dead neurons.
It looks like this activation function cannot be derived. We fix this by simply setting the derivation to 0 or 1 at x=0.
{python} torch.nn.ReLU()
Torch allows us to set an in-place parameter. If set to true, it doesn't create a copy of the input, it saves memory and helps with computations, however if the layer is needed later (skip connections or other) that is obviously an issue.
Advantages
- So cheap to compute
Neural networks that use this activation function after each/most layers are called Relu Neural Network
Leaky ReLU
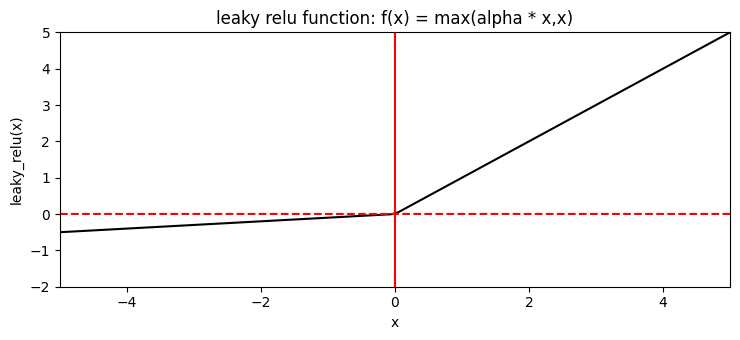
Trivia
In one course a model using the ReLU activation function with linear layers was called a "relu neural network". I wouldn't use this term outside of this one course though, I don't think its an established term.